PhD Research
Performance modelling of distributed stream processing topologies⌗
Distributed stream processing systems (like Apache Storm, Heron and Flink) allow the processing of massive amounts of data with low latency and high throughput. Part of the power of these systems is their ability to scale the separate sections (operators) of a stream processing query to adapt to changes in incoming workload and maintain end-to-end latency or throughput requirements.
Whilst many of the popular stream processing systems provide the functionality to scale their queries, none of them suggest to the user how best to do this to ensure better performance. The user is required to deploy the query, wait for it to stabilise, assess its performance, alter its configuration and repeat this loop until the required performance is achieved. This scaling decision loop is intensely time consuming and for large deployments the process can take days to complete. The time and effort involved also discourage users from changing the configuration once one is found to satisfy peak load. This leads to the over-provisioning of resources.
To solve these issues a performance modelling system for stream processing queries is required. This would allow the performance effect of changes to a query’s configuration to be assessed before they are deployed, reducing the time spent within the scaling decision loop. Previous research on auto-scaling systems using performance models has focused either; on queueing theory based approaches, which require small amounts of historical performance data but suffer from poor accuracy; or on machine learning based approaches which have better accuracy, but require large amounts of historical performance data to produce their predictions.
The research detailed in this thesis is focused on showing that an approach based on queueing theory and discrete event simulation can be used, with only a relatively small amount of performance data, to provide accurate performance modelling results for stream processing queries.
We have analysed the many aspects involved in the operation of modern stream processing systems, in particular Apache Storm. From this we have created processes and models to predict end-to-end latencies for proposed configuration changes to running streaming queries. These predictions are validated against a diverse range of example streaming queries, under various workload environments and configurations. The evaluations show that for most query configurations, our approach can produce performance predictions with similar or better accuracy than the best performing machine learning based approaches, over a more diverse range of query types, using only a fraction of the performance data those approaches require.
Thesis Download⌗
You can download the full text of the thesis here, however the introduction chapter is replicated on the page below and gives a good overview of the problem and the proposed solutions.
Introduction⌗
Processing big data is not a new phenomenon in computing, it has been present since its earliest days. The only thing that has changed is what we consider big to mean. Towards the end of the last century, hundreds of thousands of items and multiple megabytes were pushing the boundaries of what was possible to process. Now, thanks to research projects like the Large Hadron Collider and the ambitions of companies like Google, trillions of items and petabytes of data need to be processed on a regular basis.
In the past, the solution to big data issues was typically to scale vertically, where the code is run on machines that have faster processors, more memory and/or larger storage. However in recent years, thanks in part to the advent of cloud computing, horizontal scaling — where computation is spread across several relatively low powered machines — has become the norm. This has led to the emergence of many distributed big data processing frameworks such as Google’s MapReduce, Apache Hadoop and Apache Spark. These Distributed Batch Processing Systems (DBPS) allow for huge amounts of data, 20 petabytes a day or more, to be processed. However, these systems are focused on processing large volumes of data, not on processing high velocity data.
In recent years it is not only the size of the data that needs processing which has required innovation, but also the rate at which this data arrives and the timeliness of operations performed on it. Social networks, such as Twitter, are focused on “What is happening now?” and so need to analyse trends across the hundreds of millions of daily posts their users produce in real time. This real time requirement means that batch processing systems which run daily, hourly or even every minute are not appropriate. This has led to the development of Distributed Stream Processing Systems (DSPS) such as Apache Storm, Spark Streaming and Apache Flink.
DSPS are often combined with the DBPS mentioned above into what is commonly referred to as the Lambda Architecture. This architecture allows operators to leverage the low latency of a stream processing system for queries which are time, but not accuracy, critical and use the slower batch processing system for those queries that require accurate results across a whole dataset. The Lambda Architecture has been widely adopted in industry, however running two concurrent systems obviously involves duplicated effort, additional resources and increased costs. To address this, industry has started to move towards eliminating the batch processing elements of the Lambda Architecture and using the stream processing system for all queries. This approach, known as the Kappa Architecture, requires solving several issues with the current DSPS around their message delivery guarantees, fault tolerance and automation. This focus on improving stream processing systems has led to increased interest in research related to DSPS and their operation, which in turn provided the impetus for this PhD research.
Distributed Stream Processing⌗
DSPS allow operations on streams of constantly arriving data to be distributed across a cluster of workers (physical or virtual machines). The operators form a directed graph, commonly referred to as a topology, which defines the sequence of operations on the incoming data. Figure 1 illustrates a DSPS topology, with a source component (S) that inserts data packets into the topology and several operators which consume these data packets, perform operations on them and produce zero or more new data packets to be passed downstream to the next operator in the topology.
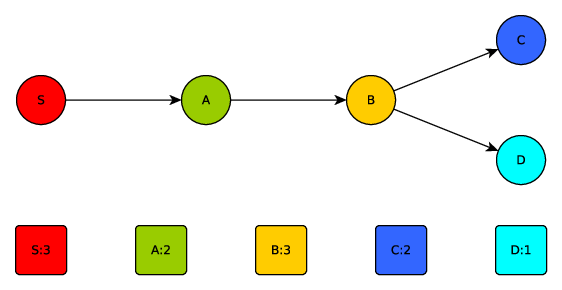
Figure 1: An example stream processing topology and replication level of each operator.
If needed, operators can be replicated across the cluster of workers to reduce latency and increase throughput. Slow operators and/or those expecting high traffic can have higher numbers of replicas, to increase parallel processing, while fast or low traffic operators may require fewer replicas to keep up with the incoming data packet arrival rate. The numbers, shown in the squares below the operators in figure 1, give an example level of replication for each operator. Figure 2 shows an example of how the copies of each of those operators could be distributed across a cluster of three workers.
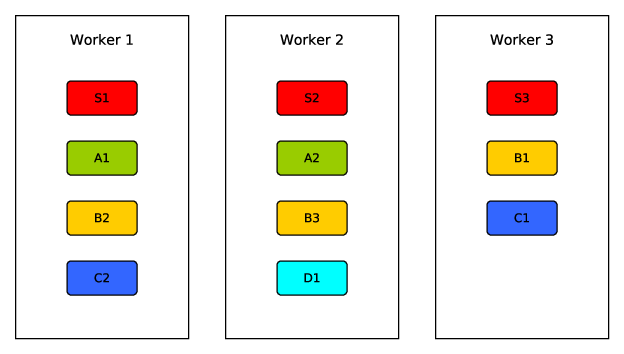
Figure 2: A cluster layout for the operators of the topology shown in Figure 1.
The creation of this operator layout on the cluster, commonly called the topology’s physical plan, is referred to as scheduling. The physical plan of a topology can have a significant effect on the performance of that topology. Placing replicas of two connected operators, which send large amounts of traffic to one another, on separate worker nodes will mean that traffic has to travel across the network, incurring additional transfer latency. Placing high traffic operators on the same node may remove the network transfer latency between them but, as these operators are now on the same machine, they are competing for the same finite resources and so this may result in slower processing of the data packets.
Topology Scaling Decisions⌗
Many of the popular DSPS provide functionality to change the physical plan of a topology whilst it is running. However, to the best of our knowledge, all but one of the mainstream DSPS have no mechanisms to automatically scale or reschedule their resources in response to the size and rate of the incoming data (the topology’s incoming workload). This means that the current DSPS rely on a human administrator’s domain knowledge and experience in order to scale a topology to the correct size to meet peak incoming workload. The administrator will typically engage in an iterative approach using the following steps:
- Choose the parallelism of each topology operator.
- Use their DSPS’s scheduler to create a physical plan for their chosen configuration. Certain schedulers may give additional control over worker node resources and operator replica placement as well as operator parallelism.
- Deploy that physical plan to the DSPS cluster.
- Wait for the deployment to finish and for the data flow through the topology to stabilise. Depending on the size of the topology this can take a significant amount of time and is often overlooked in DSPS design.
- Wait for a further period to gather performance metrics. This can involve waiting for a sufficiently high input workload to arrive (which may require waiting for a specific time of day) or the creation of an accurate test load generator.
- Assess if the topology performance is meeting the specified targets.
This schedule -> deploy -> stabilise -> analyse loop (see figure 3) is a time intensive process. In the worst case, for large, complex and high-traffic topology (like those used in production environments), finding a configuration that will maintain performance in the presence of peak input workload can take several weeks to complete.
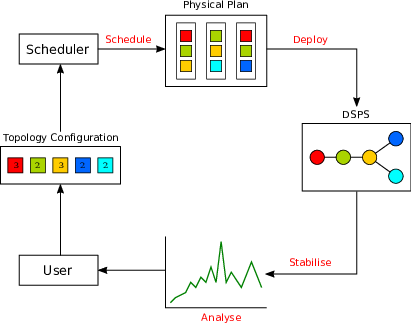
Figure 3: The schedule -> deploy -> stabilise -> analyse scaling decision loop with a human user.
Scheduling a topology’s physical plan is a known NP-complete problem, where multiple optimum plans exist for a given set of constraints. There are numerous examples in the literature of automatic scheduling algorithms that use a variety of approaches to obtain an optimum plan. However, whilst these systems allow the removal of the human administrator from the scaling decision loop, they still require multiple iterations of the full loop in order to converge on a valid plan (see Figure 4). Even the advanced machine learning algorithms, described in Chapter 3, cannot avoid the time penalty of repeated iterations of this loop.
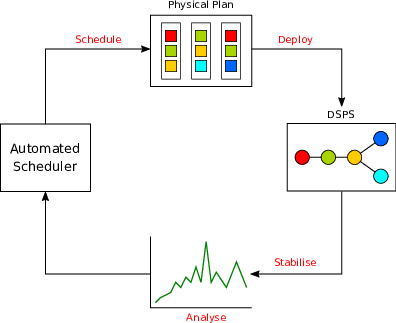
Figure 4: The schedule -> deploy -> stabilise -> analyse scaling decision loop with an auto-scaling system included.
Model-Based Scaling Decisions⌗
In order to reduce the time taken to make scaling decisions, the loop shown in Figure 4 needs to be shortened. Ideally, the time costly phases of deployment, stabilisation and analysis should be performed as few times as possible, preferably once. What is required, therefore, is a way to assess if a physical plan is likely to meet a performance target before it is deployed to the DSPS cluster.
This implies the need for a performance modelling system capable of assessing a proposed physical plan. This system should be able to use recent metrics data, collected from a running topology, and predict the end-to-end latency and throughput of that topology as if it were configured according to the proposed plan. Such a system could not only address the time taken to converge on a valid physical plan but also provides several other advantages over the current topology scaling approach described above.
Faster convergence on a valid plan⌗
The inclusion of a performance modelling system into the scaling decision loop would allow schedulers to decide whether a plan is appropriate before it is deployed, avoiding the significant costs that are incurred for that operation. This would also allow an auto-scaling system to quickly iterate to an initial deployment plan based on some preliminary metrics rather than iterating over the full scaling loop or, in the case of reinforcement learning auto-scaling approaches, waiting for an extended training period (with a sufficient variation in states) to be completed.
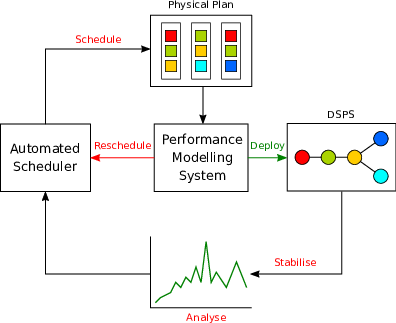
Figure 5: An auto-scaling system paired with a performance modelling system.
Figure 5 shows the effect of adding a performance modelling system into the scaling decision loop. The deployment section of the loop is short-circuited through the modelling system. Assuming an efficient modelling process, the schedule $\rightarrow$ model $\rightarrow$ deploy loop should be significantly quicker at finding a physical plan to meet a given performance target than the schedule $\rightarrow$ deploy $\rightarrow$ stabilise $\rightarrow$ analyse loops shown in Figure 3 and Figure 4.
Feedback for scheduling decisions⌗
An additional advantage that a performance modelling system would provide is detailed feedback on a proposed physical plan’s performance. The modelling system could return detailed breakdowns of aspects of the plan which did not meet given performance criteria. Bottlenecks within the topology’s data flow, overloading of individual Worker Nodes and many other issues could be identified for a proposed physical plan. The scheduler could then use this information to make more informed scaling decisions, potentially reducing the total number of iterations required to converge on a valid physical plan.
Pre-emptive scaling⌗
In order to predict the performance of a proposed physical plan, the modelling system also needs to know the expected incoming workload (Y) into the topology. The system could simply assume that the workload level will remain unchanged, but the imperative to perform a scaling action on the topology is usually due to a change in workload and so some notion of what that new workload level is likely to be must be provided.
A pessimistic approach to workload prediction could be to take the expected peak load into the topology, discerned from historical data, and find a physical plan that could perform at the target performance level (T_p) under that load. However, this would lead to significant over provisioning and ignores one of the key features of DSPS, namely the ability to scale dynamically as input workload changes.
If incoming workload levels could be forecast some time (tau_f) into the future, then this would allow an auto-scaling system to model the effect of that predicted workload level (Y_hat) on the currently running physical plan. If the predicted performance level (T_p^{Y_hat}) of the proposed physical plan does not meet the required performance level (T_r) for the predicted workload level, then the system can pre-emptively begin the scaling operations. Ideally tau_f would be longer than the time taken to perform the modelling process (tau_mode) and for the topology scaling operations to complete (tau_scale). If tau_f > tau_model + tau_scale then the scaling operation could be completed before the new workload level was expected to arrive and the performance target could be maintained. This processes is illustrated in Figure 6.
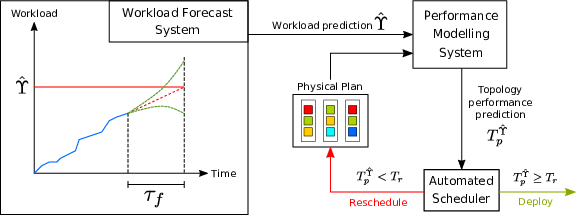
Figure 6: The pre-emptive scaling process made possible by combining a performance modelling system with an incoming workload forecasting system.
Forecasting incoming workload levels is an entire field of study in itself. However, several off-the-shelf approaches exist for forecasting of time series data and could be used in conjunction with the performance modelling system. There are also issues around when to perform the forecasting and how to take forecasting and performance modelling error into account in decision of when and how to begin scaling. However, it is clear that a performance modelling system is a key requirement in any pre-emptive scaling system.
N-version scaling⌗
Another significant advantage to having a modelling system for proposed physical plans is that it allows the output from different schedulers to be compared. When using the current scaling decision process (see figure 3) or the auto-scaling processes proposed in the literature (see figure 4), only a single scheduler can be used. The scaling loop occupies a significant amount of time and therefore repeating the loop additional times for different schedulers would be prohibitively expensive, not to mention the fact that currently there is no way for a scheduler to differentiate between different physical plans. However, with a modelling system, multiple physical plans can be produced and compared in parallel.
As scheduling of DSPS topologies is an NP-Complete problem there are diverse approaches for producing physical plans for a given topology. Each has been designed with a specific use case and set of underlying assumptions in mind. Depending on the application that the topology is designed for, as well as its deployment environment, one or another of these proposed schedulers will be more appropriate. With a performance modelling system the user of a DSPS would not need to determine a priori which scheduler was the most appropriate for their use case. They, or an automatic scaling system, could simply employ a range of schedulers and use the modelling system to compare their performance and select the best one.
This approach also has advantages with regard to possible errors in the scheduler implementations. For example, if a given scheduler has a bug, multiple other implementations with the same optimisation goals (computing resource, network traffic, etc.) could be compared in parallel and matching plans from a majority of schedulers chosen to reduce the chances of a ‘buggy’ plan being chosen. This is a form of N-version programming from fault tolerant software design.
Summary⌗
DSPS provide the functionality to process high volumes of data at high velocity. However, whilst many of these systems provide the functionality to scale up (and down) to match incoming workloads, all but one (Apache Heron) have no way to do this automatically. Proposed solutions in the literature focus on the problem of creating optimal physical plans and not on the time taken to deploy, stabilise and check that a scaling decision has met a given performance target.
The introduction of a performance modelling system, for proposed physical plans from any of the many schedulers proposed in the literature (see Chapter 3), would allow the expensive scaling decision loop to be shortened. Such a performance modelling system provides several advantages:
- Reduces the time to find a viable physical plan to meet a given performance SLA.
- Can provide detailed feedback on the performance of a proposed plan that can be used to inform the scheduler’s future decisions.
- When coupled with a workload prediction system, can facilitate pre-emptive scaling by allowing a physical plan that can satisfy the SLA in the face of the predicted workload to be deployed before that workload arrives.
- Allows multiple physical plans from different scheduler implementations to be compared in parallel. Allowing the user to avoid the task of choosing the most appropriate scheduler for their workload and application domain.
Research aims⌗
The research described in this thesis has several aims:
- Create a performance modelling system for DSPS queries (topologies).
- The system should have the ability to model any proposed physical plan created by a scheduler implementation. This includes various streaming operator types (windowing, joining, splitting, etc.) and connections between them (load balanced or key based routing).
- The system should be able to provide performance estimates using a minimum amount of input data and avoid the need for extensive calibration or training periods. Such periods would remove the advantage of adding a performance modelling system by requiring many deploy -> stabilise cycles to be carried out in order to provide the calibration/training data.
The central hypothesis of this thesis is that the above aims can be achieved using an approach based on queuing theory and discrete event simulation, without the need to resort to using machine learning based approaches and the onerous training and data requirements they entail (see Chapter 3 for more details).
Thesis Structure⌗
Chapter 2 describes the process of choosing the example DSPS, Apache Storm, and goes on to describe in detail the relevant aspects of Storm’s operation. Chapter 3 details the previous work in the field of DSPS automation and performance modelling. Chapter 4 describes the approach taken to modelling the performance of Apache Storm topologies. Chapter 5 analyses the accuracy of the modelling system and evaluates its performance. Finally, chapter 6 discusses the results of the doctoral research and looks at future areas of study.
In addition to the main chapters, there are several appendices with supporting information: appendix C details the implementation of the performance modelling system and its supporting infrastructure; whilst appendix D details the outcome of applying the performance modelling approach developed for Apache Storm to Twitter’s Heron DSPS as part of a four month internship with the company.
Related Publications⌗
During the course of my PhD research I have contributed to the following peer-reviewed publications:
Cooper, T. (2016) ‘Proactive scaling of distributed stream processing work flows using workload modelling: Doctoral symposium’, in Proceedings of the 10th ACM International Conference on Distributed and Event-based Systems - DEBS ’16. pp. 410–413.
This paper, produced in the first year of my PhD, introduces my research area, defines the problem I was addressing and outlines my proposed solution. The initial focus of my research, as described in this paper, was on pre-emptive scaling, however this subsequently changed to focus solely on the accuracy of the topology performance model.
Kalim, F., Cooper, T., et al. (2019) ‘Caladrius: A Performance Modelling Service for Distributed Stream Processing Systems’, in Proceedings of the 35th IEEE International Conference on Data Engineering. pp. 1886–1897.
During my internship at Twitter, detailed in appendix D, I applied the modelling techniques I developed for Apache Storm (see Chapter 4) to Twitter’s Heron DSPS. As well as a topology performance modelling system, I developed a workload forecasting system for Heron topologies. Following my internship, another PhD student continued to develop the modelling system (called Caladrius) as part of a subsequent internship and this paper details our combined work in collaboration with Twitter’s Real Time Compute team.
Cooper, T., Ezhilchelvan, P. & Mitrani, I. (2019) ‘A queuing model of a stream-processing server’, in 2019 IEEE 27th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS). pp. 27–35
As part of the development of the model used for the predicting the latency of the Storm executors, various standard queuing models were considered. However, none were deemed to meet the unique characteristics of Storm’s queue implementation. In the end a discrete event simulator was used to model the Storm executors (see appendix B). Towards, the end of my PhD I collaborated with Isi Mitrani and Paul Ezhilchelvan to develop new analytical solutions for modeling these unique queueing systems. This paper details both exact and approximate solutions for modelling the stream processing queues, as well as looking at possible optimisations of the queue parameters.